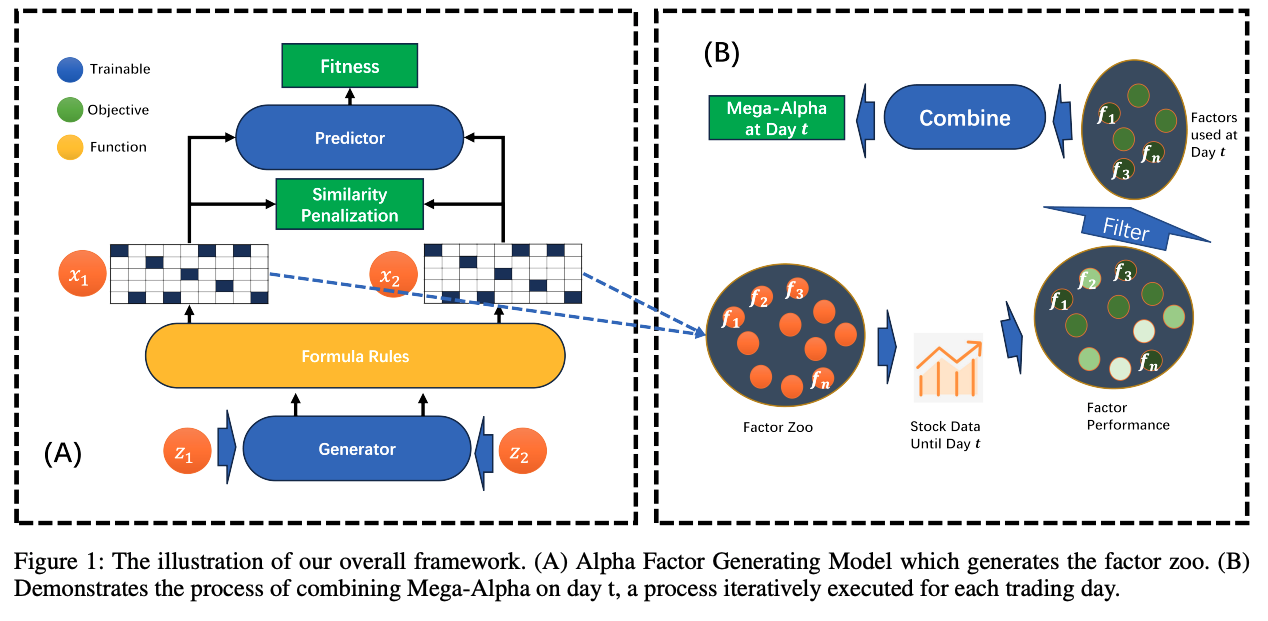
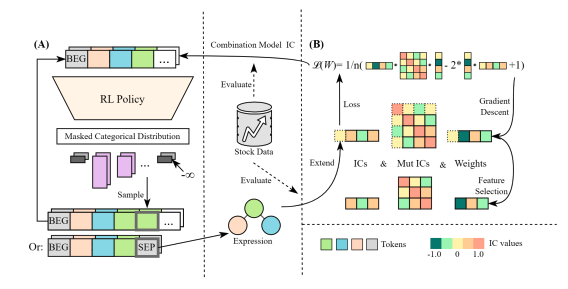
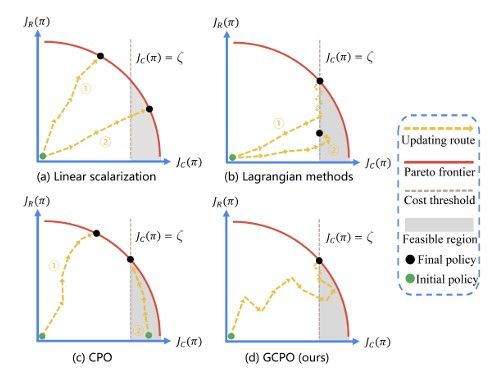
Constrained Reinforcement Learning (CRL) burgeons broad interest in recent years, which pursues maximizing long-term returns while constraining costs. Although CRL can be cast as a multi-objective optimization problem, it is still facing the key challenge that gradient-based Pareto optimization methods tend to stick to known Pareto-optimal solutions even when they yield poor returns (eg, the safest self-driving car that never moves) or violate the constraints (eg, the record-breaking racer that crashes the car). In this paper, we propose Gradient-adaptive Constrained Policy Optimization (GCPO for short), a novel Pareto optimization method for CRL with two adaptive gradient recalibration techniques. First, to find Pareto-optimal solutions with balanced performance over all targets, we propose gradient rebalancing which forces the agent to improve more on under-optimized objectives at every policy iteration. Second, to guarantee that the cost constraints are satisfied, we propose gradient perturbation that can temporarily sacrifice the returns for costs. Experiments on the SafetyGym benchmarks show that our method consistently outperforms previous CRL methods in reward while satisfying the constraints. [paper]