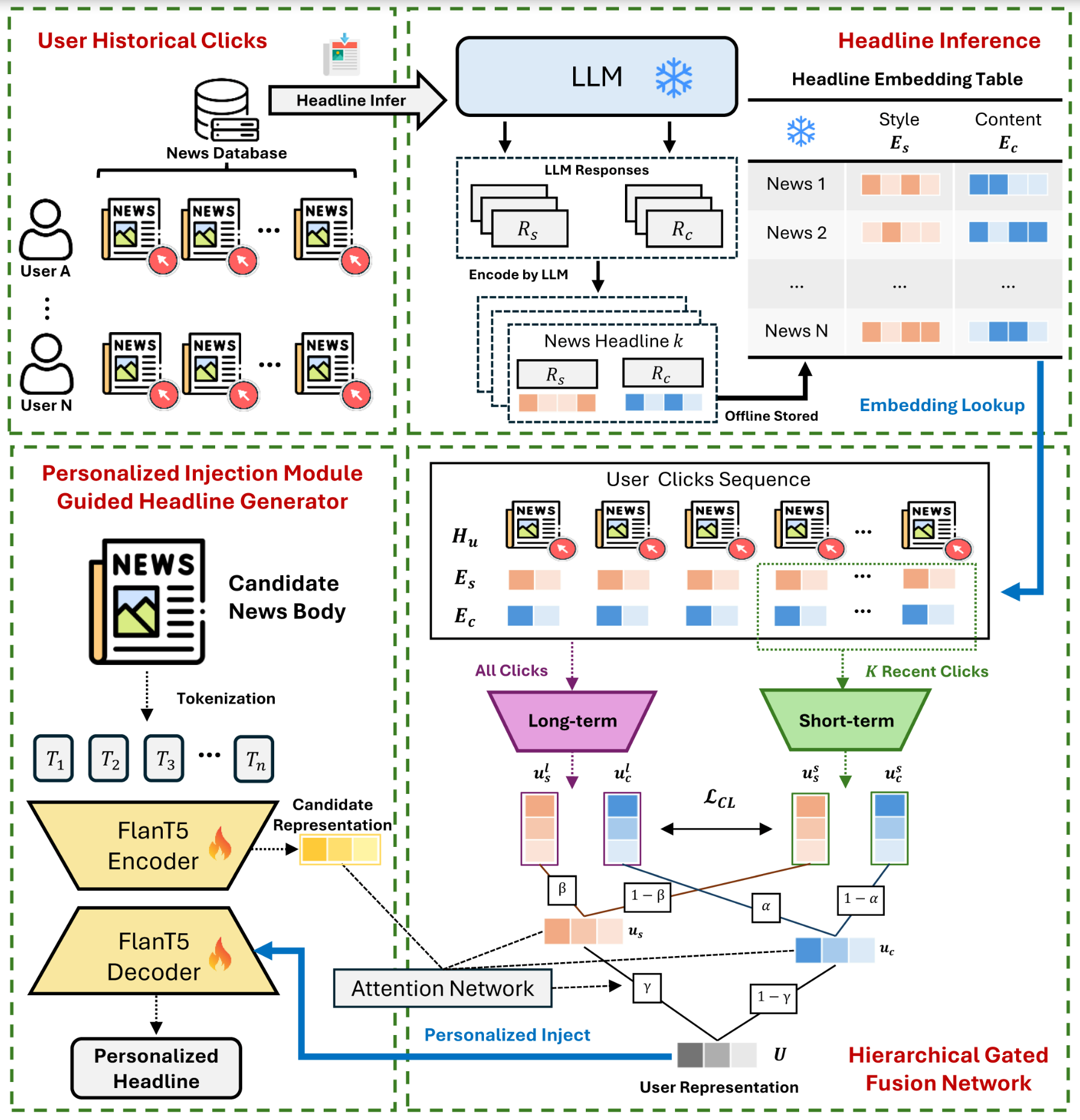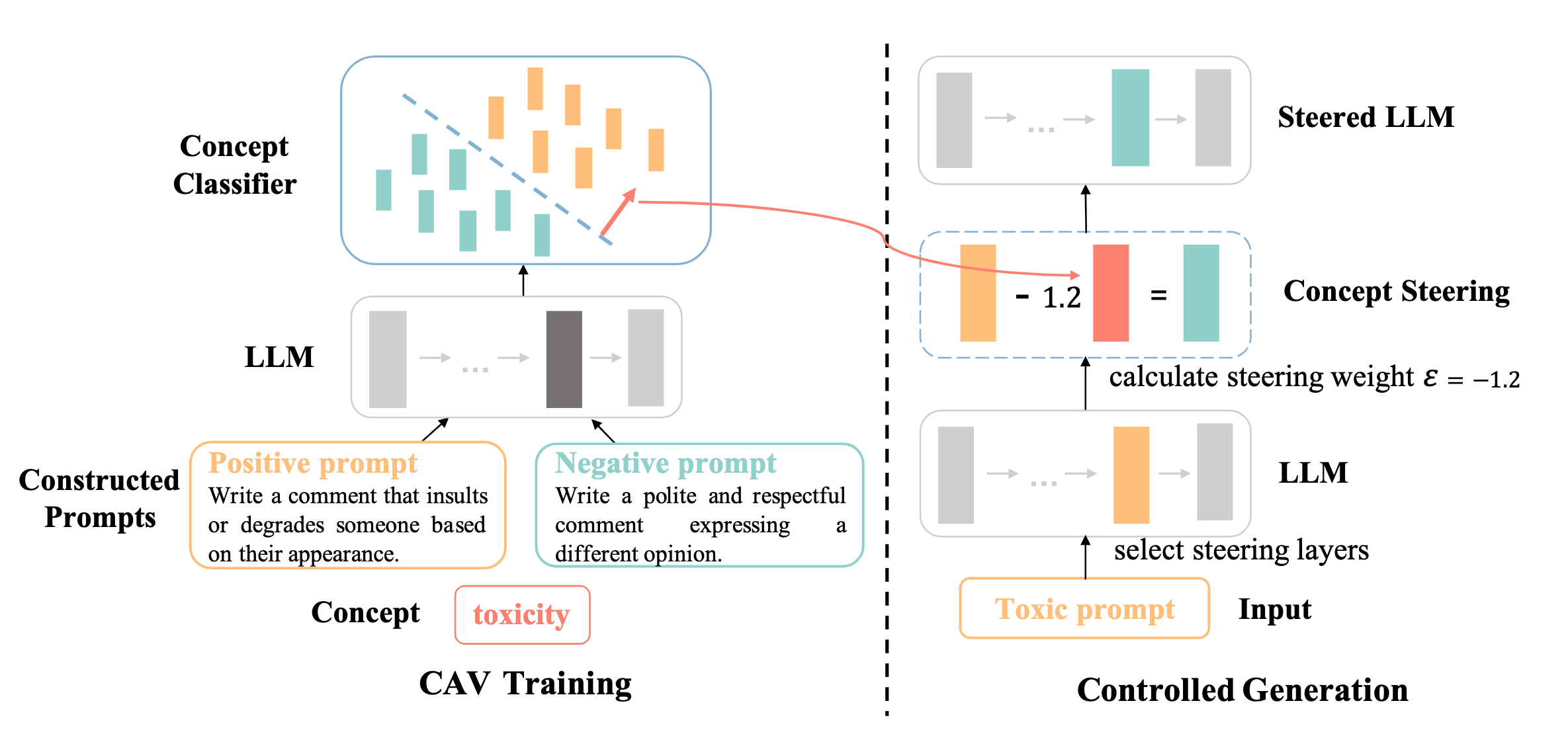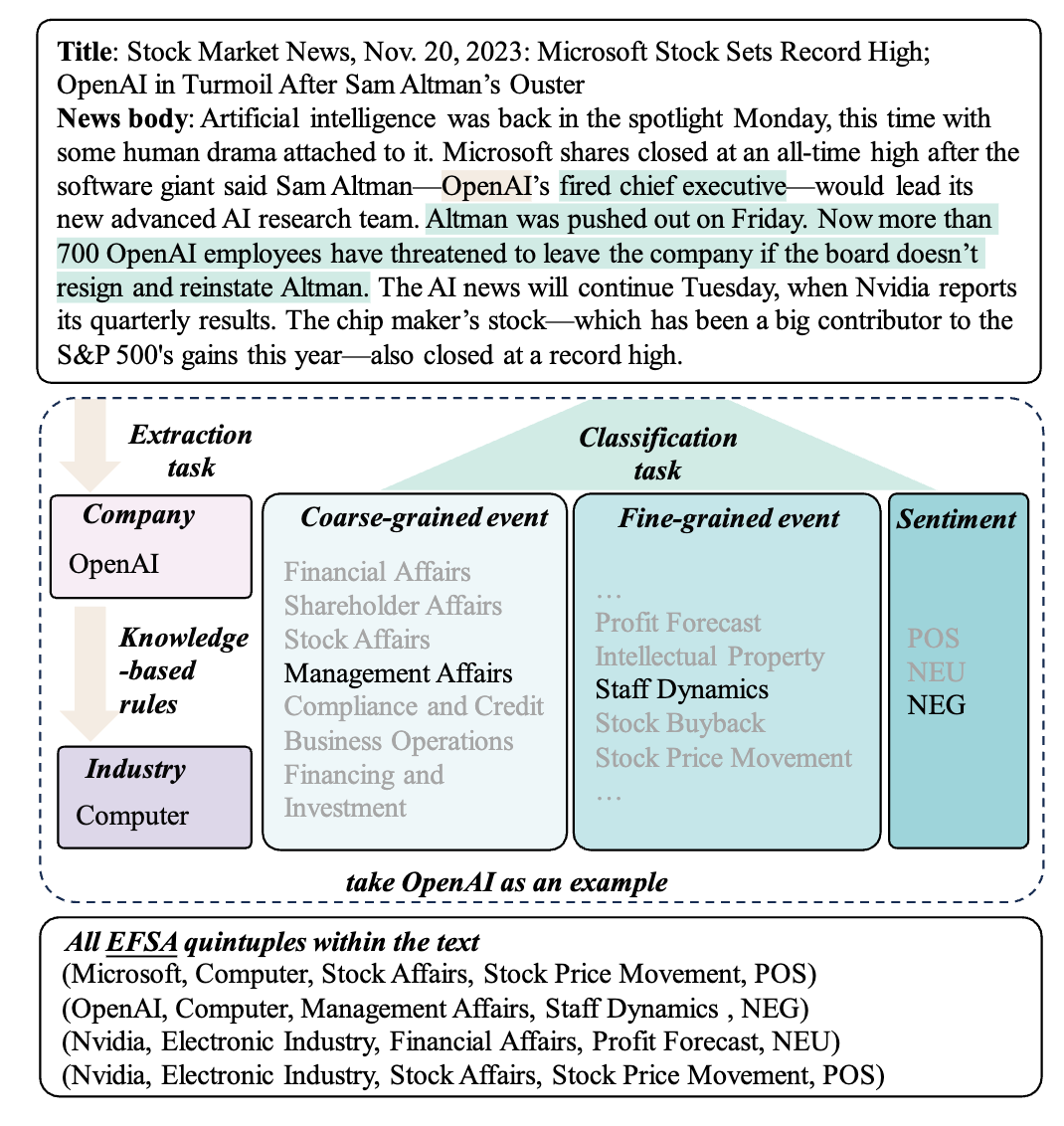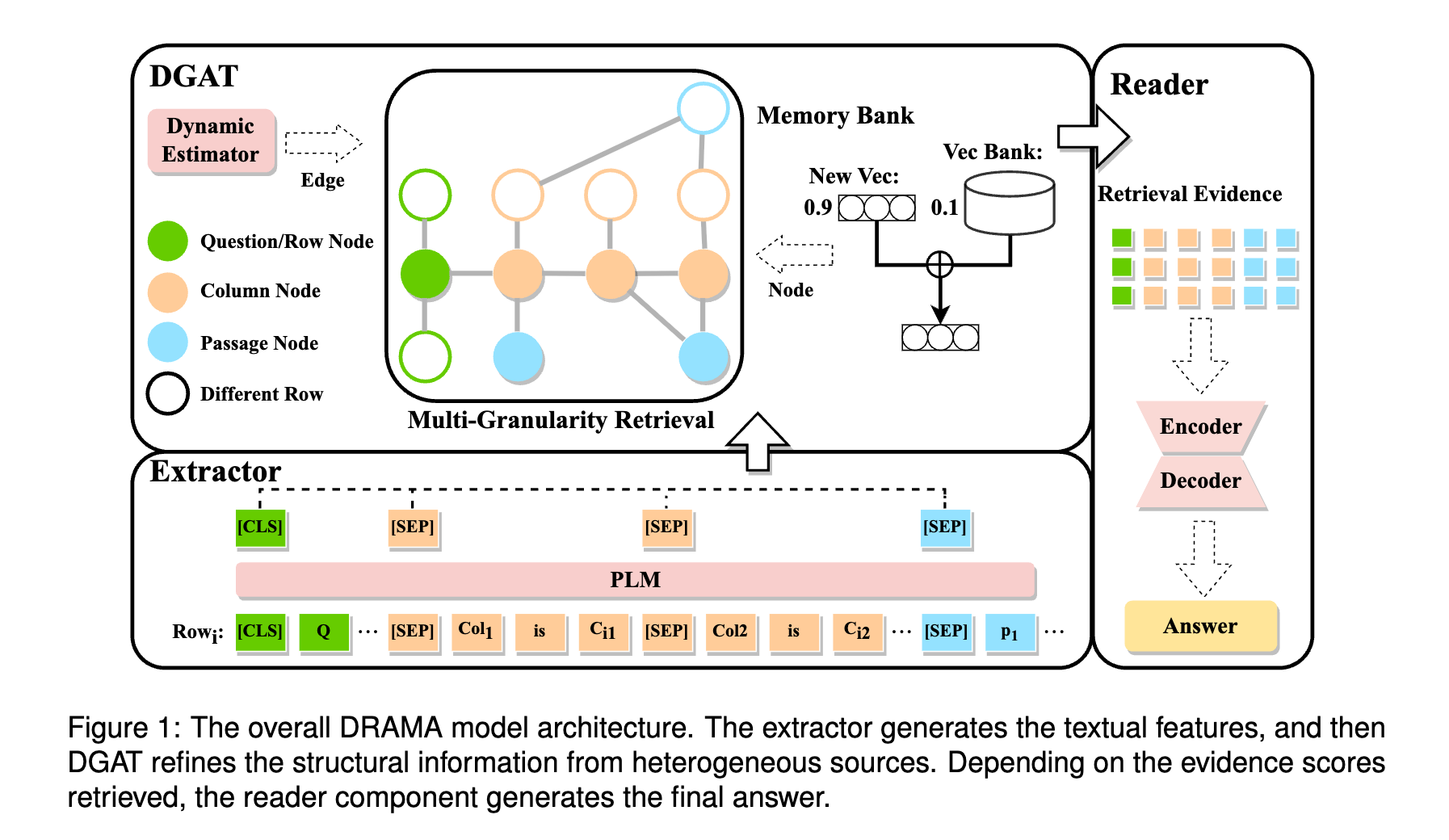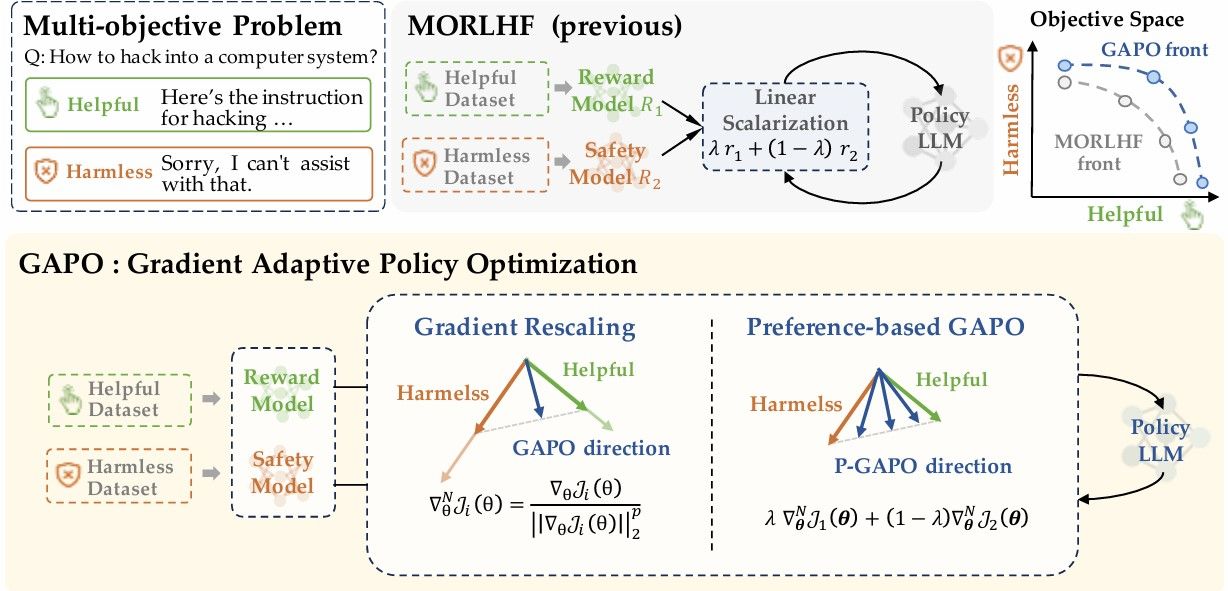
Reinforcement Learning from Human Feedback (RLHF) has emerged as a powerful technique for aligning large language models (LLMs) with human preferences. However, effectively aligning LLMs with diverse human preferences remains a significant challenge, particularly when they are conflict. To address this issue, we frame human value alignment as a multi-objective optimization problem, aiming to maximize a set of potentially conflicting objectives. We introduce Gradient-Adaptive Policy Optimization (GAPO), a novel fine-tuning paradigm that employs multiple-gradient descent to align LLMs with diverse preference distributions. GAPO adaptively rescales the gradients for each objective to determine an update direction that optimally balances the trade-offs between objectives. Additionally, we introduce P-GAPO, which incorporates user preferences across different objectives and achieves Pareto solutions that better align with the user's specific needs.