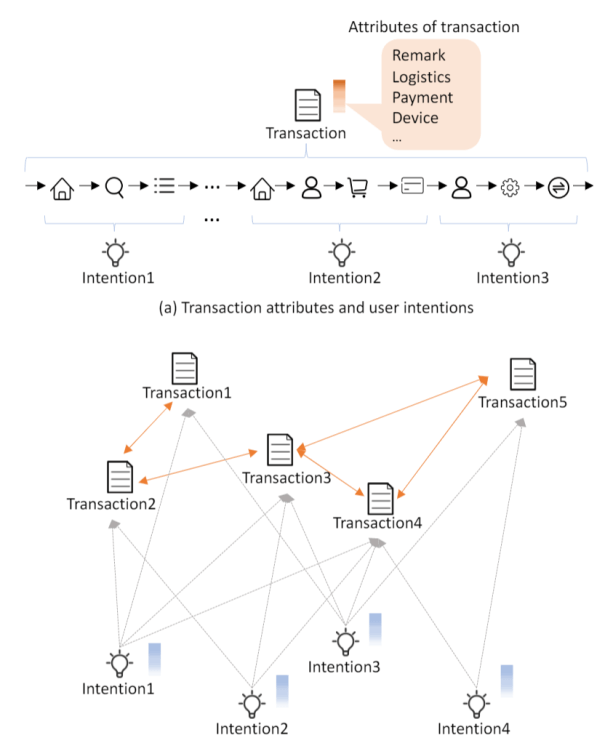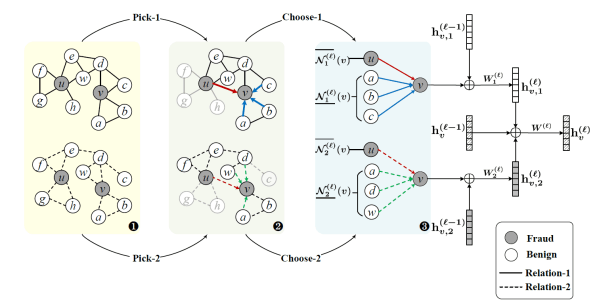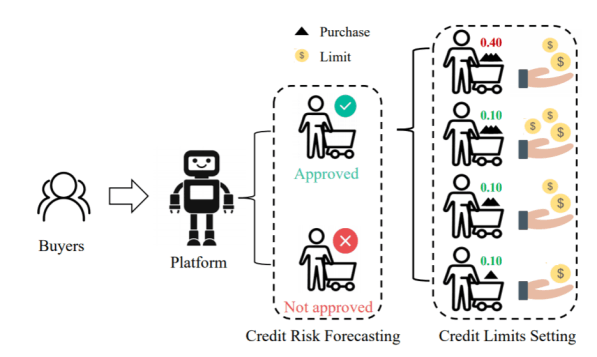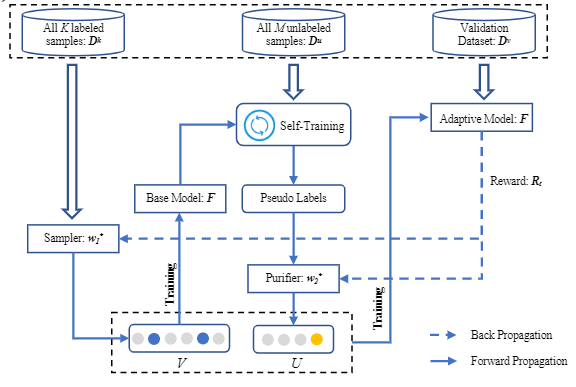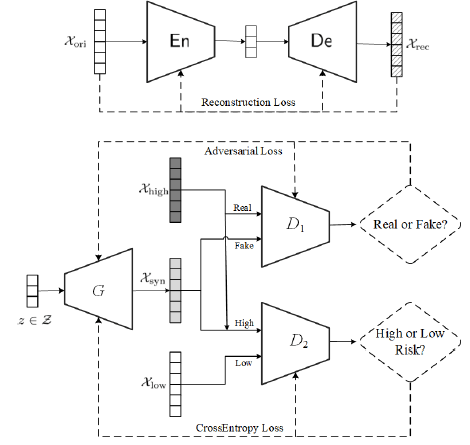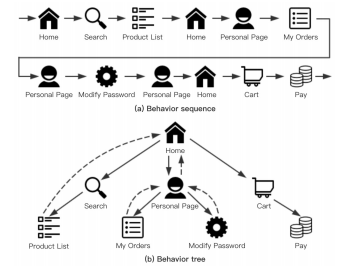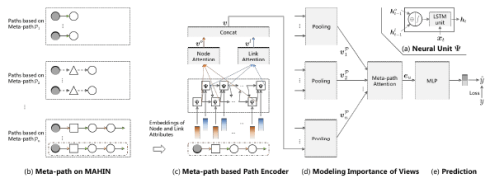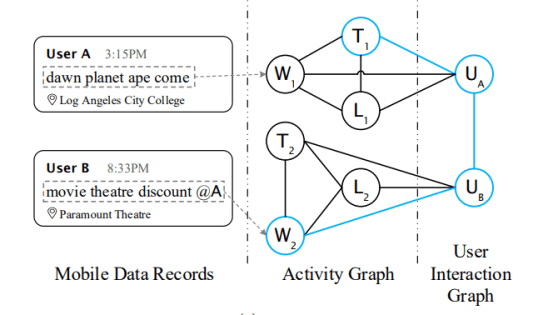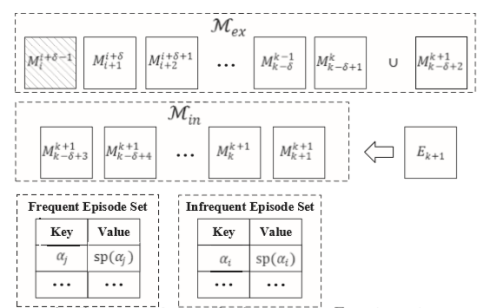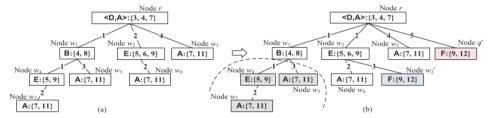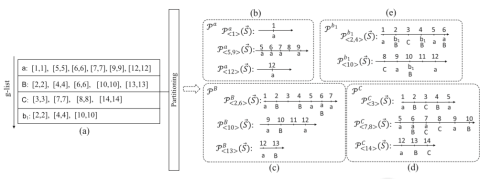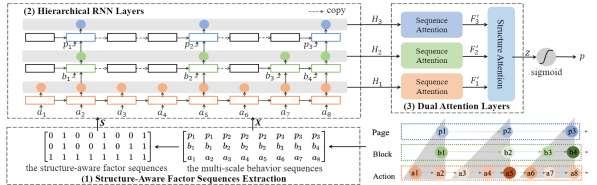
In this paper, we adopt multi-scale behavior sequence generated from different granularities of web page structures and propose a model named SAH-RNN to consume the multi-scale behavior sequence for online payment fraud detection. The SAH-RNN has stacked RNN layers in which upper layers modeling for compendious behaviors are updated less frequently and receive the summarized representations from lower layers. A dual attention is devised to capture the impacts on both sequential information within the same sequence and structural information among different granularity of web pages. [paper]